
AI可解释性
Published:
简介
CNN通常由一些卷积块(卷积层+激活层+池化层)和全连接层组成。 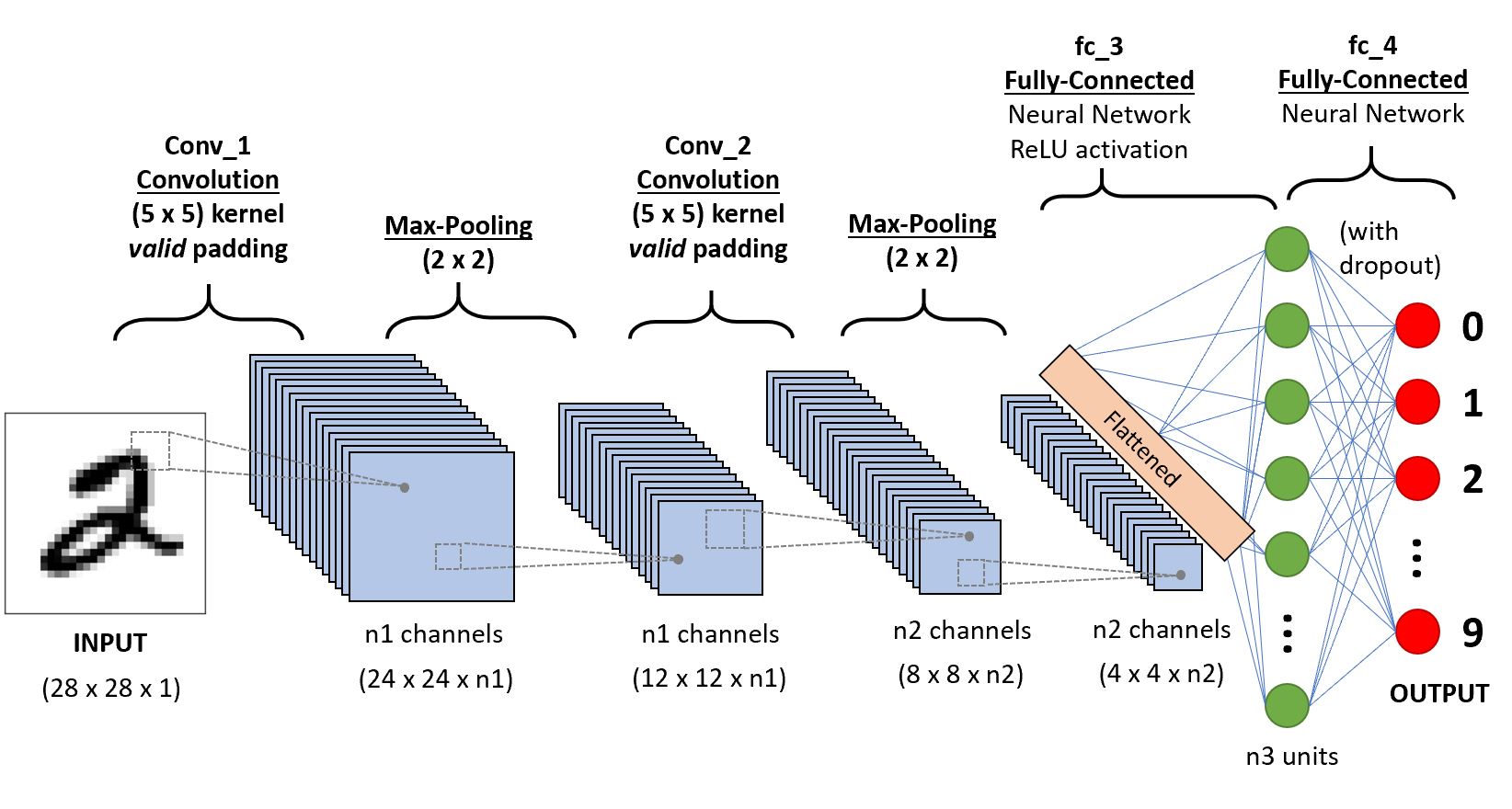
CNN的可解释性可以通过以下几种方式进行。
特征图可视化
通过直接展示中间层的特征图(一般要归一化到0-256之间),观察经过每一层卷积之后图片的变化。如下图。  上图为某CNN 5-8 层输出的某喵星人的特征图的可视化结果(一个卷积核对应一个小图片)。可以发现越是低的层,捕捉的底层次像素信息越多,特征图中猫的轮廓也越清晰。越到高层,图像越抽象,稀疏程度也越高。这符合我们一直强调的特征提取概念。
上图为某CNN 5-8 层输出的某喵星人的特征图的可视化结果(一个卷积核对应一个小图片)。可以发现越是低的层,捕捉的底层次像素信息越多,特征图中猫的轮廓也越清晰。越到高层,图像越抽象,稀疏程度也越高。这符合我们一直强调的特征提取概念。
可视化卷积核
想要观察卷积神经网络学到的过滤器,一种简单的方法是获取每个过滤器所响应的视觉模式。我们可以将其视为一个优化问题,即从空白输入图像开始,将梯度上升应用于卷积神经网络的输入图像,让某个过滤器的响应最大化,最后得到的图像是选定过滤器具有较大响应的图像。  更多图片和解释见此文
更多图片和解释见此文
把目标特征图通过DeConv, unpool, unrelu等逆向操作,映射回原图的分辨率
从而得到下面2张图。图中前几层看起来是纹理,后几层是更高级的综合性的信息


问题1: 为什么上面2张图中后面的特征图反而像素更高?难道不是后面的特征图的尺寸更小,像素更低吗? 答案1: 因为这并不是直接的特征图可视化,而是DeConv: 把中间层的特征,一层一层反传到输入端口,使得特征图的尺寸逐步放大到和输入图片相同 (原文:”map these activities back to the input pixel space, showing what input pattern originally caused a given activation in the feature maps”)。
问题2 这个DeConvnet生成的图,输入是什么?是最后一个卷积块的输出(全连接层之前)? 答案2 论文原话:”To examine a given convnet activation, we set all other activations in the layer to zero and pass the feature maps as input to the attached deconvnet layer”.
问题2:backpropagation, deconvnet 和guided backgpropagati的区别是什么? **答案2 导向反向传播与反卷积网络的区别在于对ReLU的处理方式。在反卷积网络中使用ReLU处理梯度,只回传梯度大于0的位置,而在普通反向传播中只回传feature map中大于0的位置,在导向反向传播中结合这两者,只回传输入和梯度都大于0的位置,这相当于在普通反向传播的基础上增加了来自更高层的额外的指导信号,这阻止了负梯度的反传流动,梯度小于0的神经元降低了正对应更高层单元中我们想要可视化的区域的激活值(https://blog.csdn.net/KANG157/article/details/113154590) 
CAM Series 类别激活图系列
CAM是一系列类似的激活图。大致原理是把最后一层卷积所输出的特征图通过加权和组成一张图。权重的设计不同产生了一系列不同的论文。  下面一个一个介绍。
下面一个一个介绍。
(GAP-)CAM (不需要梯度)
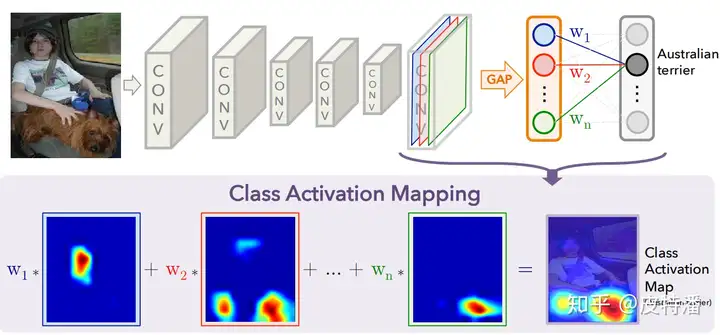
该方法的缺点是只能适用于最后一层特征图和全连接之间是GAP操作。 如果不是,就需要用户修改网络并重新训练(或 fine-tune)。所以对本文简单概括即为:修改网络全连接为GAP形式,利用GAP层与全连接的权重作为特征融合权重,对特征图进行线性融合获取CAM。
Grad-CAM
Grad-CAM和 CAM 的区别?
- CAM 只能用于最后一层特征图和输出之间是GAP的操作,grad-CAM可适用非GAP连接的网络结构;
- CAM只能提取最后一层特征图的热力图,而gard-CAM可以提取任意一层;
Score-CAM (不需要梯度)
对获取的特征图进行channel-wise遍历,对每层特征图进行上采样+归一化,与原始图片进行pixel-wise相乘融合,然后送进网络获取目标类别score(softmax后),减去baseline(全黑图片)的目标类别score,获取CIC。再进行softmax操作来保证所有CIC之和为1。最后将CIC作为特征融合权重融合需要可视化的特征层。
RAM回归激活图
Saliency map 显著性图
If we change one pixel in our input image, how much will it affect the final probability score?
Well, first of all, one way to calculate this is to perform a backpropagation and to calculate a gradient of the score with respect to this pixel value. This is easily doable in PyTorch. Then, we can repeat this process for all pixels and record the gradient values. As a result, we will get high values for the location of a dog. Note, that in this example we get a “ghostly image” of a dog, signifying that the network is looking in the right direction!
为什么Saliency map似乎没有CAM那么火呢?
Occlusion sensitifity 遮挡敏感度

可视化工具与项目
参考文献:
- https://rpmarchildon.com/wp-content/uploads/2018/06/RM-CNN-Schematic-1.jpg
- https://miro.medium.com/max/638/0*qgBQt9dMbUtntbpn.jpg
- https://blog.csdn.net/fu6543210/article/details/80407911
- https://www.tinymind.net.cn/articles/3dedb66b996232
- https://hackmd.io/@machine-learning/ByaTE80BI#ZFNetDeconvNet-Summary-and-Implementation
- https://datahacker.rs/028-visualization-and-understanding-of-convolutional-neural-networks-in-pytorch/
- https://zhuanlan.zhihu.com/p/269702192
- https://blog.51cto.com/u_14411234/3115810
- https://github.com/utkuozbulak/pytorch-cnn-visualizations#inverted-image-representations
Leave a Comment